Overview
DynamoDB の Scan の挙動について以下のエントリで調べましたが、FilterExpression を指定した場合の Query の挙動について実際に API で Query を叩いた場合と、AWS Management Console で表示したときで挙動が異なっていたので、ついでに調べた備忘録です。
どういう挙動だったか
ある GSI を Key に指定し、Filter Expression を追加して Query API を叩いて取得した Item の Count 数と AWS Management Console 上で返ってくる Item の個数が、同じ Filter Expression を使っていた、同様のクエリのはずなのに異なっていた、という挙動です。
Conclusion
結論から先に言ってしまうとこれは Scan について調べたときと全く同じでした。
Scan のときと同様、AWS Management Console 上で DevTool を開いてレスポンスを調べた結果が以下です。
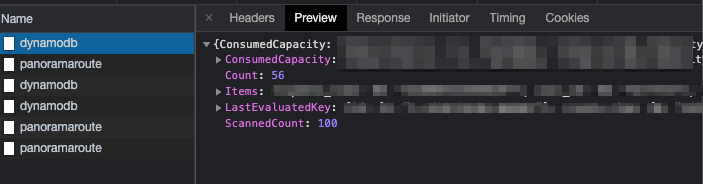
どういうことかというと、Filter した結果が Count に入っていて、Count で指定した分を UI でリクエストされる分だけ繰り返し Fetch してた、ということでした。
DynamoDB のクセ的なもの
ここで分かったのは Scan にしろ、Query にしろ、ある母集団の結果を返す、という挙動は同じであり、それが全件走査結果なのか、Partitioning された結果なのかの差は関係なかったです。
そしてもう1つは DynamoDB の Filter Expression は文字通り フィルタ であったことです。
1リクエスト当たり取得した母集団に対して、DynamoDB 側でフィルタをかけて、要素数を 間引いてる だけでした。言ってしまえば、クライアント側で絞り込みを実装してるようなものですね。それを DynamoDB の API の中でやってくれている、という挙動でした。
Filter Expression はフィルタであってクエリでない、この理解を間違っていて、意図した結果をクライアントに返せない実装になってしまってました。
DynamoDB について学んだこと
ここ数日 DynamoDB を永続的なデータストアとして使ってるケースにおいて、色んなクエリを叩けるわけではなく、基本的に全件走査を避けつつ、要求される仕様の中でどんなクエリが叩かれるのか?言い換えると、そのユースケースを実現するためのクエリのパターンは何か?ということを DynamoDB を使う上では常に意識する必要がある、ということです。
全然柔軟じゃないなーと思う反面、何かユースケースを追加する依頼が来たときにどれくらいの本気度でユースケースを考えているのか?を確認するモチベーションになります。どれくらい雑でいいのか?ちゃんと厳密に色んなケース(それこそクエリだったり、結果として返ってくるデータセットの並び順など含め)を想定しないといけません。
DynamoDB は GSI に PK/RK というかなりキツイ制約があるので、このすり合わせのモチベーションを高く持てるのがいいところだなと思いました。DynamoDB に限らず、NoSQL だったり NewSQL と呼ばれるものを使う場合は、ユースケースを実現するためのクエリパターンをデータ設計の段階から頭に入れておくことが必須ですね。